Abstract
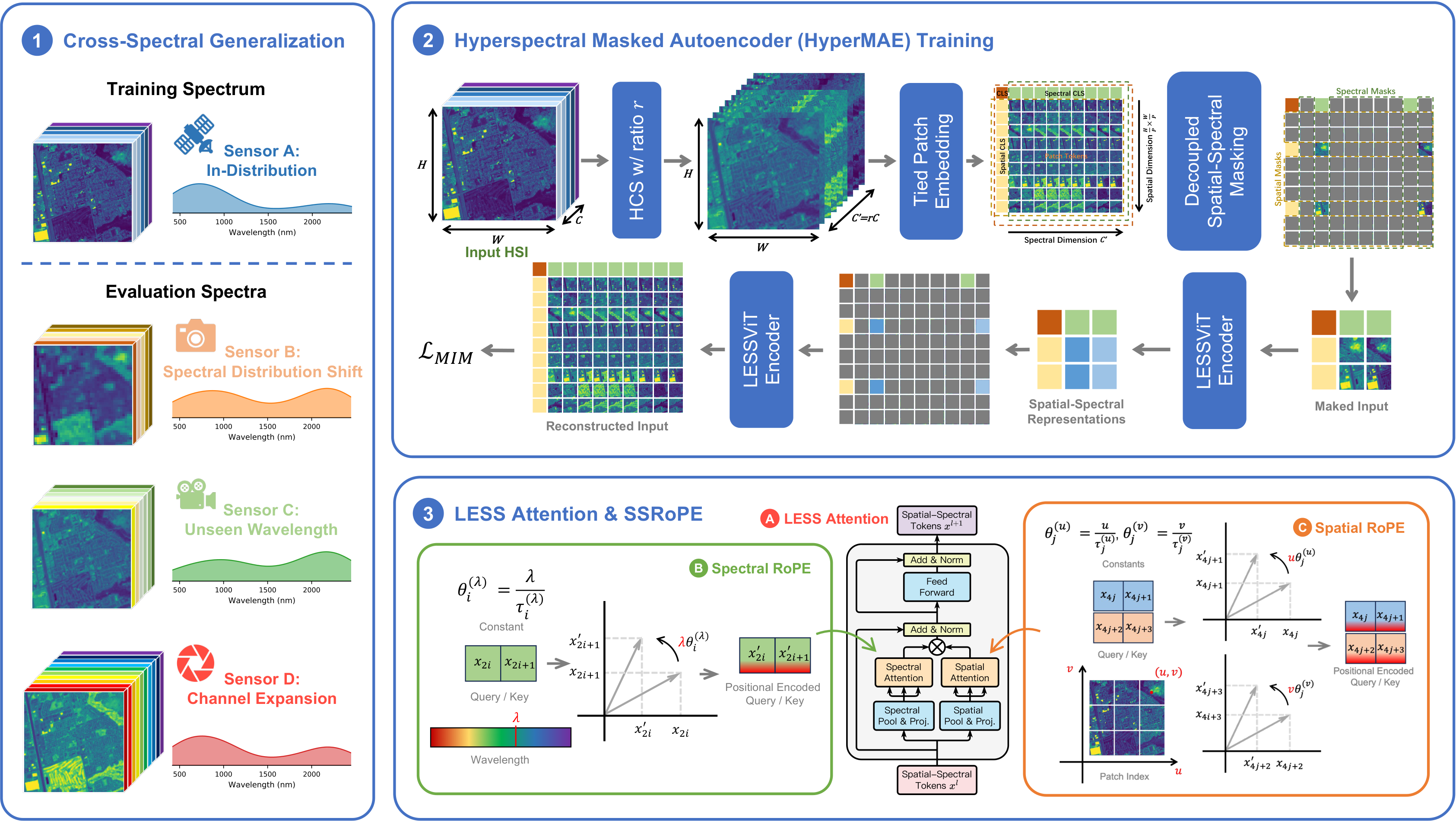
Figure: Overview of LESSViT. ① Cross-spectral generalization setting: train on a fixed spectral configuration and evaluate across sensors with varying wavelength coverage and channel configurations. ② HyperMAE pretraining with decoupled spatial–spectral masking and hierarchical channel sampling for scalable and robust learning. ③ LESS Attention with SSRoPE for efficient spatial–spectral modeling.
Key Contributions
-
1
LESS Attention — a structured low-rank factorization of spatial–spectral attention that reduces complexity from O(N²C²) to O(rNC), enabling explicit and scalable joint spatial–spectral modeling across hundreds of hyperspectral channels.
-
2
LESSViT — a channel-agnostic spatial–spectral Vision Transformer with wavelength-aware positional encoding (SSRoPE), enabling consistent and robust modeling under varying spectral configurations across sensors.
-
3
HyperMAE — a hyperspectral masked autoencoder pretraining framework with decoupled spatial–spectral masking and hierarchical channel sampling, making pretraining tractable under high channel dimensionality and robust to spectral variation.
Method
LESSViT satisfies three key requirements for cross-spectral generalization: channel-agnostic tokenization, explicit spatial–spectral modeling, and computational scalability. It integrates four tightly coupled components:
[CLS] tokens for structured aggregation.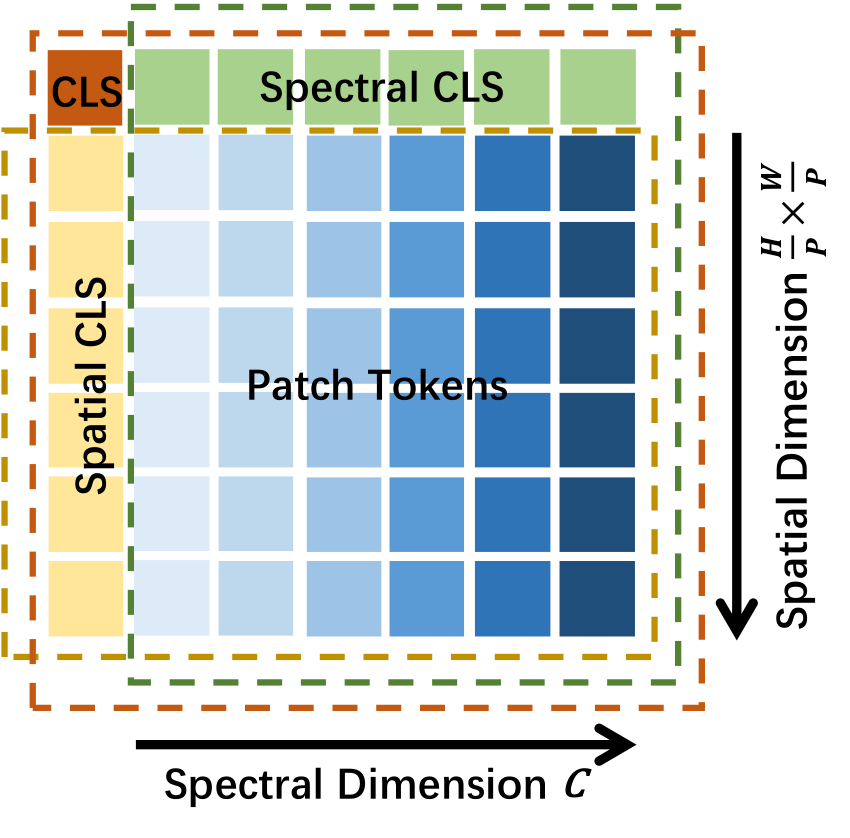
(a) Spatial-Spectral Tokenization. The tied patch embedding converts a hyperspectral image into a grid of spatial–spectral tokens with spatial, spectral, and global [CLS] tokens.
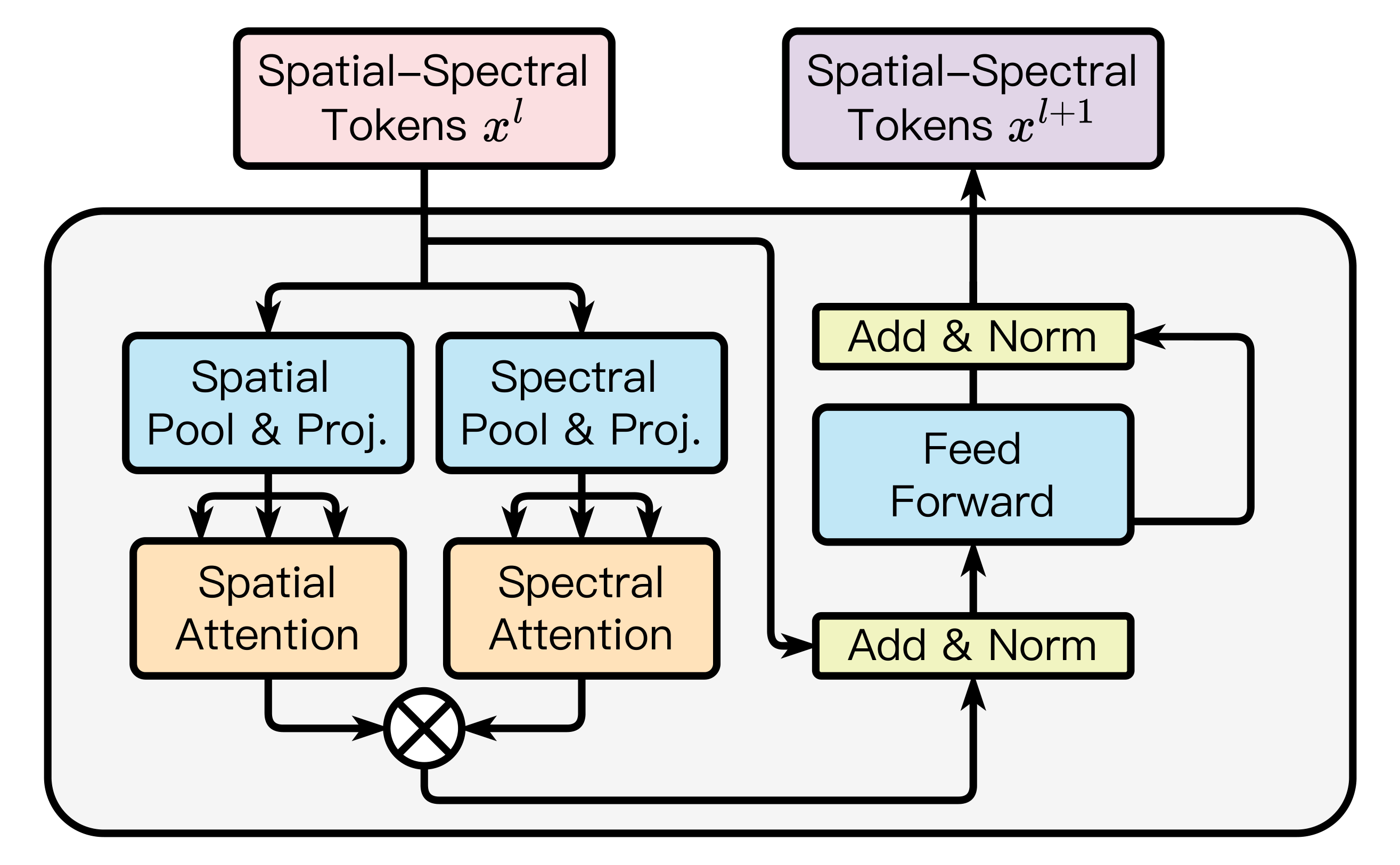
(b) LESS Attention Block. The LESS block factorizes spatial and spectral attention via structured decomposition, enabling efficient modeling of joint spatial–spectral interactions.
Cross-Spectral Generalization Benchmark
We evaluate LESSViT on SpectralEarth, a large-scale hyperspectral pretraining dataset and evaluation benchmark built on EnMAP (202 channels, 30 m resolution). Models are pretrained and fine-tuned on a fixed channel set (C120VN+) and evaluated under four spectral configurations that emulate cross-sensor variability:
120 channels: 80 VNIR + 40 SWIR. Training and in-distribution evaluation configuration.
120 channels: 40 VNIR + 80 SWIR. Same count as training, complementary spectral distribution.
82 channels entirely disjoint from training. The most challenging out-of-distribution scenario.
All 202 channels. Tests generalization when additional bands beyond the training set are available.
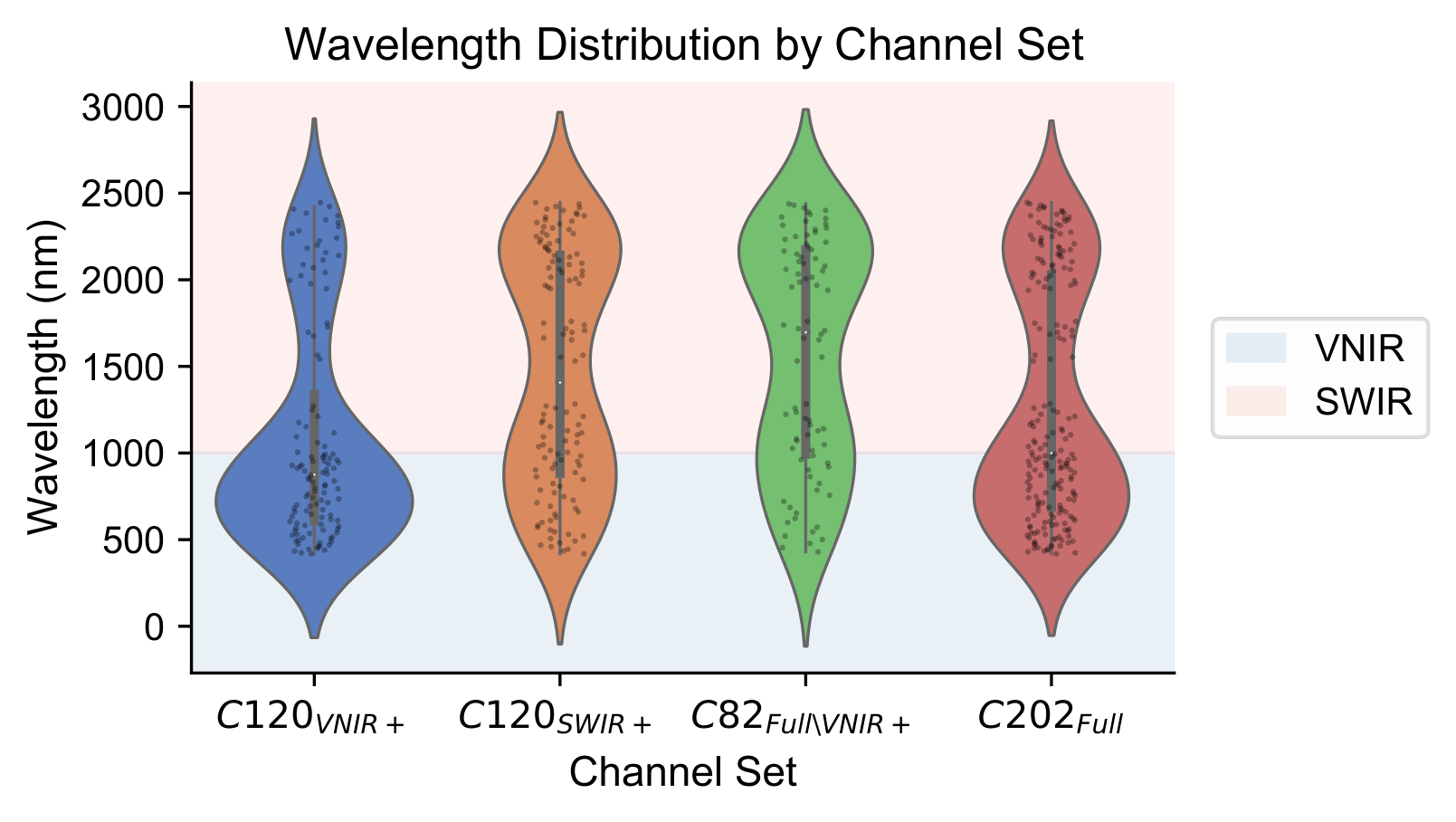
Figure: Wavelength distributions of the four channel configurations. C120VN+ and C120SW+ have identical channel counts but complementary spectral distributions (spectral shift). C82 is entirely disjoint from C120VN+ (unseen wavelengths), and C202 includes all channels (channel expansion).
Downstream Datasets
We evaluate on five geospatial labeling products covering segmentation and multi-label classification across diverse land cover types and geographic regions:
| Dataset | Region | Task Type | Metric |
|---|---|---|---|
| CDL | USA | Crop Type Segmentation | mIoU ↑ |
| EuroCrops | Europe | Crop Type Segmentation | mIoU ↑ |
| CORINE | Europe | Land Cover Classification | mAP ↑ |
| BDFORET | France | Forest Type Segmentation | mIoU ↑ |
| BNETD | Côte d'Ivoire | Land Cover Segmentation | mIoU ↑ |
Results
We compare LESSViT against three state-of-the-art baselines: SpectralViT (re-trained on C120VN+ for a fair comparison under the same protocol), HyperSigma, and DOFA (using released pretrained weights). All models are fine-tuned on C120VN+ for 20 epochs and evaluated across the four spectral configurations without any adaptation. Bold = best per column. Relative drops (↓) are computed as (ID − OOD)/ID.
Segmentation & Classification Results
LESSViT achieves the best performance on 14 out of 15 task–configuration pairs and the lowest average relative drop across all OOD settings, demonstrating improved robustness under spectral variation. SpectralViT achieves stronger in-distribution performance, reflecting its specialization to the fixed spectral configuration.
| Model | CDL (mIoU ↑) | EuroCrops (mIoU ↑) | CORINE (mAP ↑) | BDFORET (mIoU ↑) | BNETD (mIoU ↑) | Avg. Rel. Drop (%) ↓ | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120SW+ | C82 | C202 | |
| SpectralViT | 70.29 | 13.71 ↓80% | 6.87 ↓90% | 5.43 ↓92% | 70.27 | 33.65 ↓48% | 43.13 ↓39% | 48.09 ↓32% | 79.21 | 35.82 ↓55% | 38.23 ↓52% | 38.40 ↓52% | 76.28 | 48.25 ↓37% | 48.43 ↓36% | 48.57 ↓36% | 43.54 | 14.54 ↓67% | 16.92 ↓61% | 18.76 ↓57% | 57 | 56 | 54 |
| HyperSigma | 39.45 | 15.91 ↓60% | 16.48 ↓58% | 13.83 ↓65% | 56.07 | 51.04 ↓9% | 50.41 ↓10% | 51.42 ↓8% | 68.54 | 40.00 ↓42% | 25.78 ↓62% | 48.50 ↓29% | 64.23 | 49.59 ↓23% | 48.69 ↓24% | 49.52 ↓23% | 25.80 | 17.54 ↓32% | 16.37 ↓37% | 18.93 ↓27% | 33 | 38 | 30 |
| DOFA | 37.65 | 18.11 ↓52% | 17.37 ↓54% | 12.97 ↓66% | 54.61 | 42.20 ↓23% | 29.57 ↓46% | 34.64 ↓37% | 54.04 | 36.87 ↓32% | 48.33 ↓11% | 33.51 ↓38% | 57.60 | 52.26 ↓9% | 33.84 ↓41% | 50.11 ↓13% | 25.20 | 18.08 ↓28% | 18.36 ↓27% | 18.88 ↓25% | 29 | 36 | 36 |
| LESSViT ours | 51.78 | 38.92 ↓25% | 28.51 ↓45% | 46.52 ↓10% | 56.86 | 46.55 ↓18% | 51.34 ↓10% | 54.89 ↓3% | 75.55 | 67.87 ↓10% | 58.92 ↓22% | 75.54 ↓0% | 62.79 | 58.81 ↓6% | 54.00 ↓14% | 62.46 ↓1% | 31.27 | 26.16 ↓16% | 18.87 ↓40% | 28.33 ↓9% | 15 | 26 | 5 |
Impact of Proposed Modules
Ablation comparing SSRoPE positional encoding against SIREN, and the effect of hierarchical channel sampling (HCS) ratio rHCS. Models use a ViT-S backbone pretrained with HyperMAE for 50 epochs. SSRoPE consistently improves performance under spectral shift settings. Lower rHCS reduces pretraining time by 17% with minimal impact on downstream performance.
| Config. | PE | rHCS | CDL (mIoU ↑) | EuroCrops (mIoU ↑) | CORINE (mAP ↑) | BDFORET (mIoU ↑) | BNETD (mIoU ↑) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | C120VN+ | C120SW+ | C82 | C202 | |||
| Default | SSRoPE | [0.2, 0.3] | 40.04 | 41.22 | 35.60 | 40.50 | 52.52 | 46.94 | 47.49 | 49.78 | 70.74 | 68.30 | 67.11 | 69.61 | 57.30 | 58.22 | 54.39 | 58.11 | 28.04 | 24.24 | 22.37 | 26.14 |
| w/o SSRoPE | SIREN | [0.2, 0.3] | 28.79 | 29.60 | 30.58 | 29.82 | 50.45 | 45.77 | 46.01 | 47.27 | 70.32 | 69.48 | 64.68 | 69.89 | 55.51 | 54.14 | 53.89 | 54.41 | 25.41 | 21.51 | 20.89 | 23.08 |
| High rHCS | SSRoPE | [0.4, 0.5] | 40.93 | 40.87 | 35.88 | 39.13 | 52.06 | 51.54 | 48.70 | 51.37 | 69.68 | 69.04 | 64.61 | 69.83 | 59.81 | 58.19 | 54.45 | 58.85 | 28.95 | 25.77 | 23.76 | 26.44 |
Inference Latency vs. Channel Count
LESSViT maintains near-constant inference latency as channel count increases from C=10 to C=200. ChannelViT, which applies full explicit spatial–spectral attention with O(N²C²) complexity, exhibits rapidly growing latency and runs out of memory (OOM) at C=200 on a 144 GB GPU.
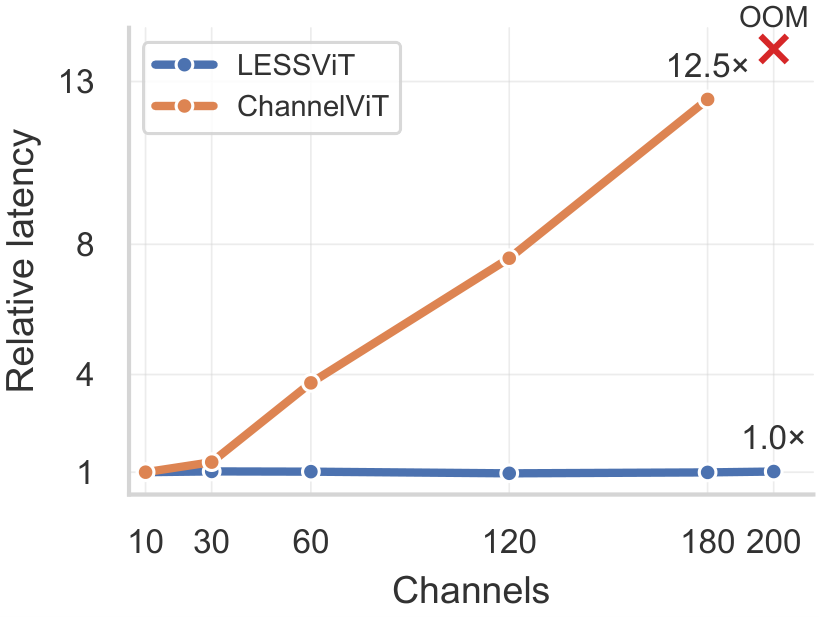
Figure: Normalized inference latency vs. channel count (normalized to C=10). LESSViT scales with near-constant latency while ChannelViT becomes OOM at C=200, confirming that LESS Attention effectively decouples computational cost from spectral dimensionality.
Segmentation under Spectral Configuration Shift
Qualitative comparison of LESSViT and SpectralViT under all four spectral configurations. In the in-distribution setting, SpectralViT produces more detailed segmentation maps due to its smaller patch size. Under cross-spectral generalization, SpectralViT exhibits large coherent misclassifications especially under spectral shift and channel expansion, while LESSViT maintains more stable predictions across all configurations.

Figure: Qualitative segmentation results. PRGB denotes pseudo-RGB visualization of hyperspectral inputs; GT denotes ground-truth segmentation masks. Background pixels are masked out in predicted maps for clarity.
Citation
If you find LESSViT useful in your research, please cite our paper: